Motivation
Background
Active Learning is a repetitive process that utilizes a learning algorithm to search for the most informative data for the existing model, rather than training it on the entire dataset.Three general learning scenarios for active learning:
- In Member Query Synthesis, the active learning algorithm generates a new unlabeled instance within the input space and queries the human expert for labeling.
- In Stream-based Selective Sampling, the unlabeled data is continuously being sent from the data source to the active learner and the active learning needs to decide if it asks the human expert to label the current data based on a query strategy.
- In Pool-based Sampling, the most common scenario, most informative data samples are selected from the pool of unlabeled data samples based on some sampling strategies or informativeness measure. Then, the human expert will provide the correct label for these unlabeled data samples. Different from stream-based selective sampling, it focuses on more than one data sample at a time.
Three main strategies to select the subset of data that is most informative to the current model:
- In Committee-based Strategies, we will build different models and use the models’ predictions to determine the most informative data. The data is considered as most informative if there is maximum disagreement in predictions from the models. The disagreement can be measured by entropy or KL-Divergence.
- In Large margin-based Strategies, the distance to the separating hyperplane is used to measure the model’s confidence or certainty on unlabeled data.
- In Posterior probability-based strategies, the estimation of class probabilities and the posterior probability distribution are used to determine whether the unlabeled data sample should be queried for label or not. This strategy can be used with any type of model which has the ability to predict output probabilities for class membership. The posterior probability distribution indicates the model’s confidence and certainty to assign the data sample to a particular class. For Posterior probability-based strategies, some common strategies to determine the most informative data samples from the probability distribution include Least Confidence, Best-versus-Second-Best (BvSB), and Entropy.
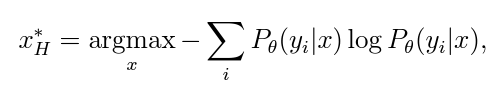
Methods
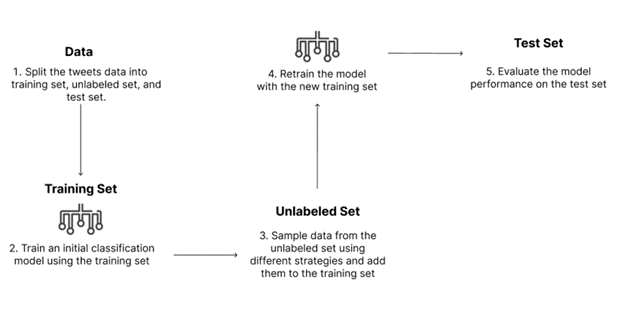
Data Preprocessing
The relevance column contained different group labels. Label 1 stands for the tweets expressing sentiment to the country of interest. Label 2 stands for tweets that express sentiment and mention the country, but the sentiment is not directed towards the country. Label 3 stands for the tweets that express no sentiment of any form. They are factual tweets that mention the country of interest. For our task, we mainly focused on building a classifier to distinguish label 1 from the rest of the labels. The sentiment column ranges from 0 to 5 and represents the sentiment of the tweet toward Chinese people or the Chinese government. For data preprocessing, we first removed the tweets that do not have a sentiment score. Then, we averaged the sentiment scores for each unique tweet by different researchers. Because we want to ensure the training data we feed into the models are correct, we eliminated those samples with decimal points due to their ambiguity. After that, we converted the numerical values into three categorical sentiments. A score between 0 and 2 will be classified as Negative. A score between 2 and 4 will be classified as Neutral. A score between 4 and 6 will be considered as Positive. After we cleaned up the predictive labels for the data, we converted the content of the tweet to lowercase, removing the symbols, links, punctuation, and stopwords. Following that, we lemmatized the content to output a cleaned version of the text. After we cleaned up the text, we transformed the cleaned text into a large language matrix using the bag of words and TF-IDF vectorizer.Model Selection
When using the Committee-based Strategies, we included Support Vector Classifier, K Nearest Neighbor Classifier, Decision Tree Classifier, Random Forest Classifier, AdaBoost Classifier as the members in the model selection committees. When using the Posterior probability-based strategies, we tried Bernoulli and Multinomial Naive Bayes, Random Forest Classifier, Logistic Regression (Ridge), and Logistic Regression (Lasso). To compare the model performance, we recorded the accuracy, precision, recall, F1 score, and specificity for each model trial with different hyperparameters.Active Learning
To find the most effective active learning strategies for our tasks, we implemented both Committee-based Strategies and Posterior probability-based strategies with different settings. The settings we tuned include the number samples we draw from the unlabeled data, data partition ratio, whether or not the data is balanced, whether or not the data is sorted by time, and different models.
Findings
Posterior probability vs. Committee based sampling strategy
We utilized several One-tailed Paired T-tests to compare the efficacy of various active learning sampling strategies with the random sampling strategy. Our null hypothesis posited that there would be no discernible difference between the mean values of the evaluation metrics (accuracy, f1-score, precision, recall, and specificity) obtained via random sampling versus those obtained through active learning sampling strategies. Our alternative hypothesis was that the mean value of the evaluation metrics obtained via active learning sampling strategy would be superior to that of the random sampling strategy. The results suggested that the Posterior probability-based sampling strategy successfully identified the most informative data for continuous model updating. Further analysis revealed that incorporating the predictions of multiple classifiers provided a more robust and less variable estimate of uncertainty, resulting in improved accuracy. Thus, calculating the entropy based on the average of classifiers' predictions did not lead to a significant increase in accuracy. The p-values obtained in tables indicated that the Posterior probability-based sampling strategy was associated with significantly smaller p-values compared to the Committee-based sampling strategy. Using a confidence level of 0.05, it can be concluded that the active learning process led to significant increases in accuracy, f1-score, recall, and specificity.| Metric | Mean | Standard Deviation | T-Statistic | P-Value |
| Accuracy | 0.0015 | 0.008 | 2.325 | 0.011 |
| F1-Score | 0.0015 | 0.007 | 2.872 | 0.002 |
| Precision | 0.0002 | 0.014 | 0.222 | 0.412 |
| Recall | 0.0025 | 0.017 | 2.105 | 0.018 |
| Specificity | 0.006 | 0.037 | 2.231 | 0.013 |
| Metric | Mean | Standard Deviation | T-Statistic | P-Value |
| Accuracy | 0.0008 | 0.01 | 0.56 | 0.289 |
| F1-Score | 0.0008 | 0.009 | 0.63 | 0.266 |
| Precision | -0.0004 | 0.015 | -0.174 | 0.569 |
| Recall | 0.0018 | 0.018 | 0.698 | 0.244 |
| Specificity | 0.0037 | 0.031 | 0.817 | 0.209 |
| Metric | Mean | Standard Deviation | T-Statistic | P-Value |
| Accuracy | 0.0065 | 0.035 | 2.519 | 0.006 |
| F1-Score (weighted) | 0.007 | 0.038 | 2.546 | 0.006 |
| Precision (weighted) | 0.0067 | 0.04 | 2.294 | 0.011 |
| Recall (weighted) | 0.0065 | 0.035 | 2.519 | 0.006 |
| Metric | Mean | Standard Deviation | T-Statistic | P-Value |
| Accuracy | -0.0147 | 0.041 | -2.469 | 0.991 |
| F1-Score (weighted) | -0.0161 | 0.045 | -2.458 | 0.991 |
| Precision (weighted) | -0.0174 | 0.046 | -2.615 | 0.994 |
| Recall (weighted) | -0.0147 | 0.041 | -2.469 | 0.991 |
Features that affect the Active Learning Performance
We investigated the impact of different settings on the accuracy of active learning by grouping the data by settings and ploting the accuracy difference graphs. In the task of relevance prediction, we observed that increasing the sampling size led to an improvement in overall accuracy. We also found that having a training set comprising only 10% of the total data, with the remaining 90% divided equally between the unlabeled and testing sets, resulted in the greatest accuracy improvements for active learning. Additionally, the Bernoulli Naive Bayes Classifier emerged as the most promising model selection option, with accuracy improvements continuing to increase as the sampling size increased to 600. However, we observed a less clear trend in the case of sentiment prediction. The graph below demonstrated that there was no significant difference in evaluation metrics between the Ridge Logistic Regression, Multinomial Naive Bayes, and Random Forest Classifier models. Moreover, the accuracy difference for the Lasso Logistic Regression model exhibited irregular changes with increasing sampling size. We thus concluded that active learning may not work as effectively for sentiment prediction using existing feature variables and models. Our findings showed that unbalanced datasets resulted in a continuously increasing trend in accuracy difference as the sampling size increased, while the variance of the accuracy difference narrowed for both relevance and sentiment prediction tasks. This led us to believe that retaining the original label ratio during the training process could have a more significant effect on active learning performance. Regarding the impact of sorting data by time on active learning, we plotted accuracy differences over sampling size. In both cases, we observed that the variances for sorted and unsorted data were significant and did not lead to a continuous improvement in evaluation metrics as the sampling size increased. Our conclusion was that while sorting data by time may result in a marginally lower accuracy, it leads to a higher recall.
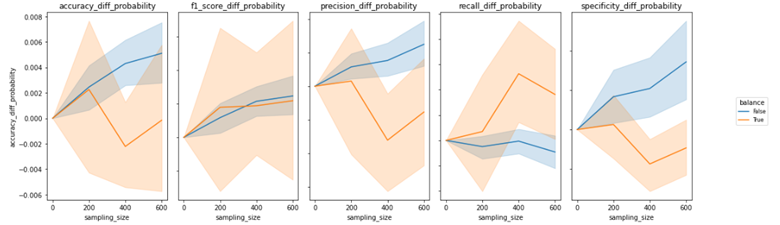
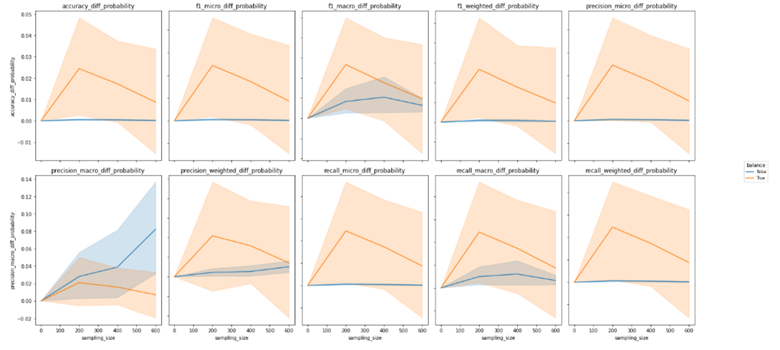
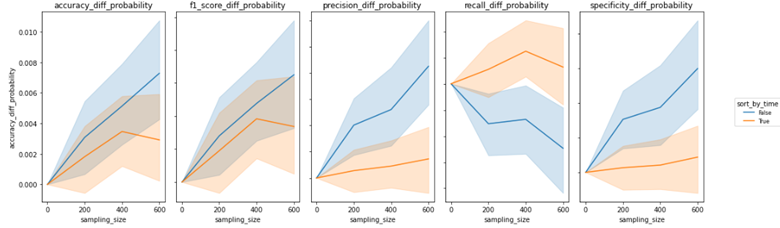
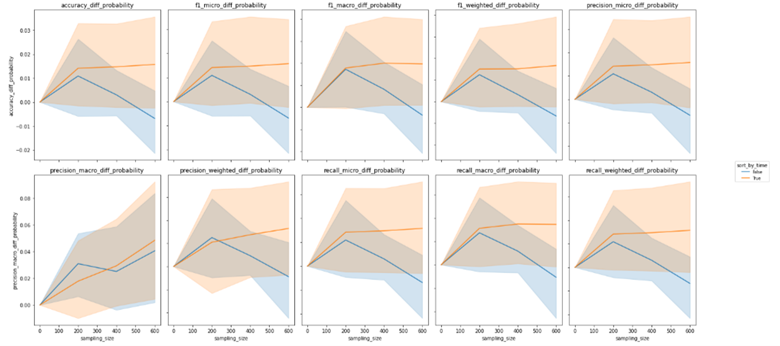
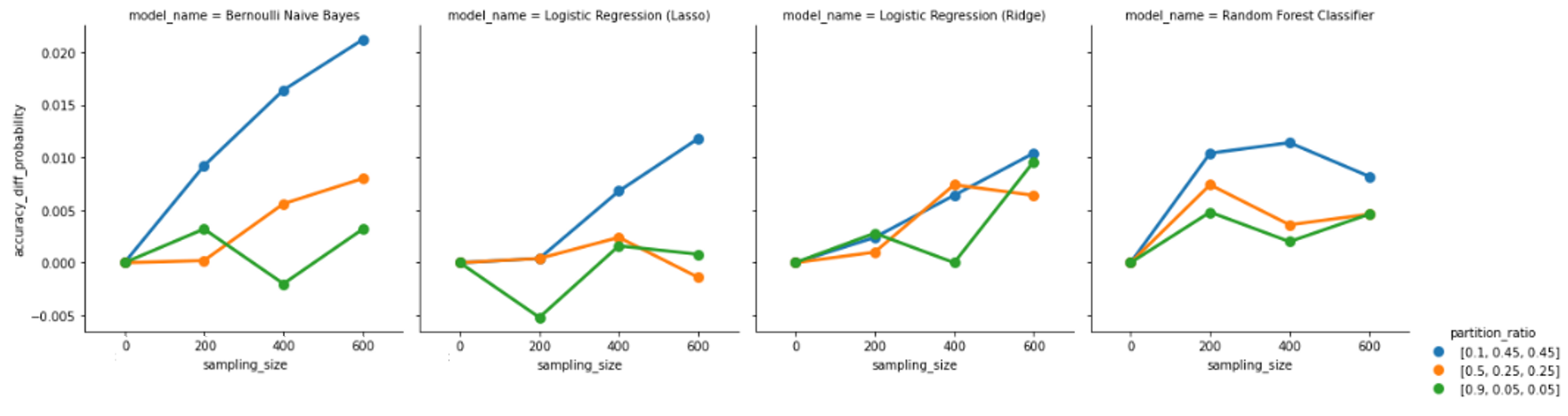
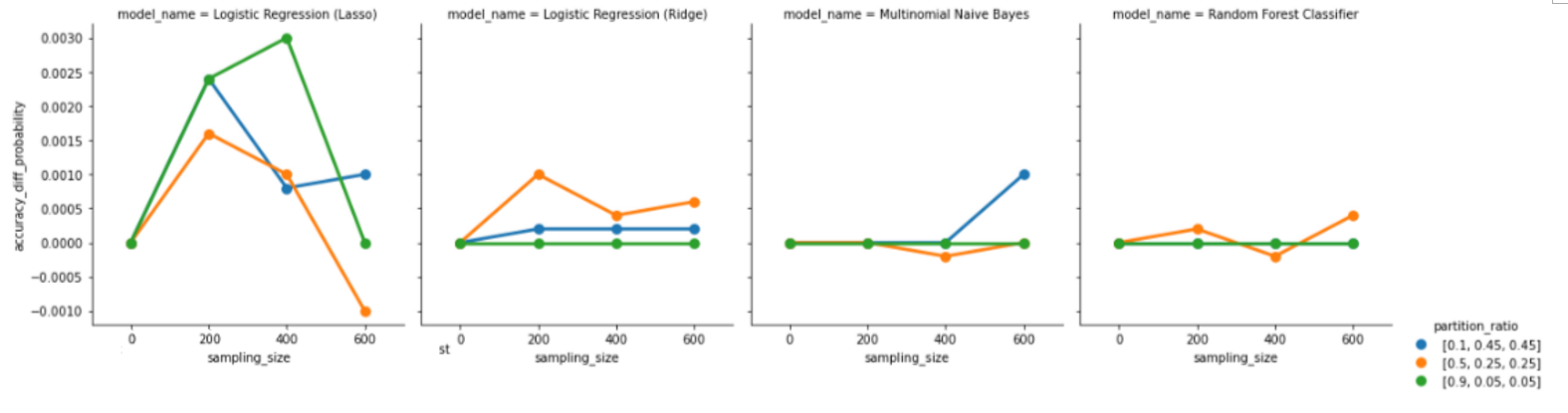
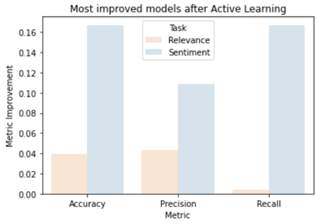
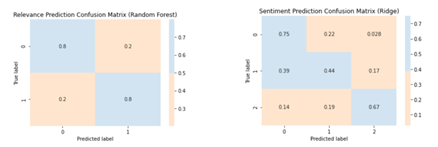
Most accurate vs. Most improved models
Regarding the task of predicting relevance, the optimal classifier trained with balanced data was found to be a Random Forest Classifier, which yielded a positive class accuracy of approximately 80%. With respect to sentiment prediction, the most accurate classifier trained with balanced data was determined to be a Ridge Logistic Regression, exhibiting respective accuracies of roughly 75%, 44%, and 67% for the negative, neutral, and positive labels. The corresponding confusion matrix for both classifiers is presented in the graph below. Additionally, the improvement of Active Learning reaches 0.16 for accuracy, 0.11 for precision, and 0.16 for recall in the sentiment prediction task. Conversely, the relevance prediction task demonstrated an overall improvement of approximately 0.04 for accuracy, 0.045 for precision, and 0.002 for recall. The relative high improvement in the Sentiment prediction task is due to the high variance in predictions with different settings. Therefore, while active learning does increase accuracy to a small extent, these improvements may be attributed to randomness and cannot be considered a significant enhancement.